|
前書き
私は現在川崎市に住むちょっと危ないおつとめプログラマです。そんな私が商売屋の観点から見たプログラミングについてペンを走らせてみることにします。これが役立つ方は少ないと思いますが、まっ、プログラマが日頃どんないい加減な仕事をしているか、その一片を覗くといった感覚で目を通して下さい。
プログラミングといっても幅のひろい言い方ですよね。これを全部網羅しようとすると大変なことです。また、よく市販されている「プログラミング技法」といったような本と同様な事柄を書いても一般的すぎてピンときません。そういったものをコピーしても仕方がないので、欲張らず今回はコーディングレベルを中心に、日頃の業務を回想しながら書くことにいたします。
よって内容につきましては、私の4年と2カ月のキャリアの独断と偏見の固まりと、7ー10数年のキャリアを持つ先輩方の偏見をプラスしたものです。
はじめにおことわりしておきますが、これらは高級言語(特にFortran,C,Pascal)におけるものなので、アッセンブラを主体に開発されている方にはあまり参考にならないかも知れません。あしからず。
コーディングというのは、えいっ!やあ!で作ってしまう人にはピンとこないかも知れませんが、機能設計、構成・詳細設計、及び各レビューが終わった後の工程なので、以下の点がすでに決定しています。
◎ルーチンの構成、数、規模.
◎各ルーチンの機能(インタフェース・ファンクション).
◎主要なテーブル(要素、型、サイズ、名称、etc.).
◎プログラムの制限事項.
◎etc.
それで、コーディングを行なう前に以下の点に注意します。
1.本当に機能を理解しているか
上記の事柄を本当に理解しているか再認識。入力は何で、どういった処理をして、何が出力されるのか。………意外とこういうのって、理解しているつもりで勘違いしていることが多いもの。作り始めてから「あれっ、ここはこうじゃないと困るなぁ」ということにもなりかねない。
2.当然ながら使用する言語を熟知する
コーディングしながら文法書を見るようでは最適なコーディングができるわけがない。………と厳しいことを言う私も、いつも文法書を持っていますがね。
3.何を最優先させるのか再認識
これは何のこっちゃ?というと、以下のどれを優先させるかということ。
◎実行スピード(高速化).
◎LMの大きさ(縮小化).
◎保守容易性.
◎テスト容易性.
◎機能拡張性.
◎移植性.
◎プログラム制限(削減).
◎作成期間の短縮(既存プログラムの引用などによる).
◎etc.
なんでこれらに優先順位をつけるかというと、要素が背反するケースが多いからなんです。
それではコーディングにおける注意事項の話に移ります。
注意事項は、スピード、LM規模、ソースの見やすさ、拡張・移植性に分けて書くことにします。結論が出ていない諸問題は最後にまとめて取り上げておきました。
1.高速化上の注意
(a)無駄な実行ステートメントがないか
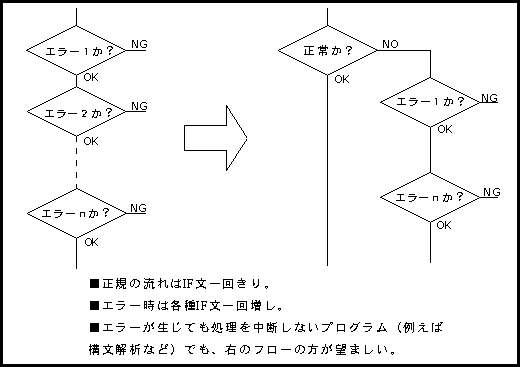
第一に注意する点はIF文のネスト。正規の流れとエラーの流れをしっかりと区別する。一般にエラー処理は多少時間がかかってもかまわないが、正規の処理は高速化すべきである。(下図参照)
次に無駄な初期化がないかチェックする。これは1本のプログラムを複数人で作成するときに生じやすい。一般に初期化は時間のかかる処理である(特にテーブルの初期化など)。
そしてデータの制限チェックの重複を除くこと。つまり、テーブルのリミット・チェックなどはバカ丁寧に全部する必要はない。例えば、外部入力を内部テーブルにジェネレートする際にこのチェックを徹底的に行い、内部から内部テーブルの処理ではよほど要素の数がランダムに変化しない限りは行わない。(保障された値)ラ(保障された値)がLimitを越えるということはないのである。もし仮に越えた場合があったとするならば、問題はこの省略したチェック処理以前にあるのであって、原因はここではないと考えるべきである。ゆえにこのチェックは保守・バグ取りには便利だが、ユーザにとってはシステムアボートもプログラムエラーストップも同じレベルなのだから、最終的にはわざわざ時間をかけて行なうものではない。入力データ(外部データ)のエラー指示さえあればいい。
まあ、これは、OSのプロテクトの堅い環境の話であるといえばそうなのだが……
(b)OBJを考慮してコーディング
例えばCの場合
a:=1;
b:=1; --> a:=b:=c:=1
c:=1;
とした方がLOADが高速に行われる。
その他、ループごとに計算する必要の無いものはループの外で一度計算して、定数のイメージでループ内で使用する。最近はコンパイラのオプティマイズレベルが高くなってきているので、これを気にする人は少なくなった。
それとRealのまるめの誤差には要注意。
(c)よく使うロジックに無駄がないか
例えばソートの場合、扱うデータの形式や量によって最適なものを選択して使用する。たかがソートといっても馬鹿にはできない。
(d)テーブルの構成
これはコーディングレベル以前の話であるが、重要なので付記しておく。
テーブルというのは基本的に、入力データを出力データにジェネレートする処理の効率を高めるためにある。バカチョン処理をするならばテーブルはいらない。よって、テーブルは用途に適したものを構築する。作成が頻繁に行われるならば作成しやすいように、参照が多いならば参照がしやすいように考える。
2.LMの規模の縮小化
最近は動作環境のメモリが大きくなりあまり気にしなくなったが、敢えて述べておくことにする。
(a)テーブル領域の共有化
例えばダイナミックアロケート。あまり使うと動作が遅くなるので注意が必要である。最近の傾向として、この手のものはLM縮小化のためではなく、つまらないプログラム制限を生じないようにするために使用される。これ、本当。
(b)共通ルーチン化
機能レベルなどが全く別でも、処理が類似していればそれらを共通ルーチン化しておく。しかし保守しにくいので商売プログラムでは行われない。
(c)バイト単位で領域を使う
各種変数において、用途により2バイト、4バイト、8バイトと使い分ける。これも保守性や拡張、移植性のためにあまり行われない。
ともかく最近の傾向としては、LMサイズは無理に小さくしなくても並でいいという風潮が蔓延している。
3.保守性・拡張性・移植性
(a)Limitの変更容易性
Limitは定数で使用し、変更が容易なようにしておく。
(b)文字コード
ASCII,EBCDICなど、変更を容易にしておく。
(c)リード・ライトはまとめておく
各ルーチンで好き勝手にリード・ライトしないで、共通ルーチンで行うようにする。
4.見やすさ
これはソースの見やすさのことであまり機能には関係しないが、作業上は重視されている。見やすさという点で一番肝心なのは書式の統一性。ゆえに通常、コーディング前にチーフがコーディング規約を決める。
(a)コメント
各ルーチンごとにヘッダ(機能,インタフェース,バージョンなどのコメント)を付ける。コメントの書き込み位置も統一性を持たせる。
(b)変数名
意味のある名前を付ける。君もやったことがあるのでは?女の子の名前だらけのコーディング。
あと、変数名の類似に注意。これはバグの原因になる。しかし大規模のプログラムを作成すると、変数名の頭文字に規則性を持たせたりするため変数名の類似が生じる。
グローバルとローカル、及び定数の名称を区別する。通常、グローバル変数は頭文字を取り決め、ローカル変数はグローバル変数と一致しない名称ならば自由とする。また定数は大文字で記述することで区別するのが普通である。
(c)下向きのコーディング
GOTO文でやたら飛びまくるコーディングはしない。
(d)1ルーチンのステップ数
1000ステップのルーチンを作ったりしない。せいぜい200ステップ程度にする。
(e)変に凝らない
意味もないのに再帰的コーディングをしたり、めったに使わないコードを得意になって使ったりしない。(あるあるある:編)
5.諸問題
一概には言えない問題。
(a)コモン
コモンは、いたるところで使用(作成・参照)できるのは便利だが、逆にそのため保守性が悪く、一度バグると収拾するのにパワーを要する。しかしデータの一括管理などリミットも多いので、現状では大規模なプログラム(1万ステップ以上)以外はなるべく使わないで引き数受け渡しとしている。とにかくケース・バイ・ケース。
(b)ルーチンの出口
1ルーチンの入口、出口がそれぞれひとつづつというのは、見やすくわかりやすい。でも処理及び言語によっては複数出口もしかたがない。例えばエラーリターンなど。
後書き
結局とりとめもない事を書いてしまったような気がしますが、コーディングについてはこんな感じですね。いやーしかしプログラミングというのははっきり言って“社内制手工業”ですねぇ。まったく効率が悪い。最近はデバッガなどの環境が良くなりつつあるけれど、それでも手工業の感は拭い去れないもんね。Σ計画だとかTRON、それにOSFだとか。動いてはいるけれど当分は変わり得ないでしょうねぇ。
|