 |
||
| 連載第四回 「マルチなCPU」 | ||
| H20/12/17 | ||
| 現在(平成20年末)主流のパソコン向けCPUといえばIA-32アーキテクチャ(俗に言うx86系CPU)を持つものでしょう。64bit機能を持っているものがほとんどになってきましたが、大部分がそれを使用せず、32bitモードで動作しているのが実情だと思います。それはとりもなおさず、現状では64bitに移行するメリットがあまり無いからでしょう。MMXレジスタが64bit、XMMレジスタ(SSE用)が128bitあり、双方とも32bitモードから自由に使えるというのも一因と思われます。(高解像度3Dグリグリのゲームとかには64bitが嬉しいでしょうけど・・・) | ||
| IA-32系CPUはインテル社製とAMD社製が主流ですが、その種類となると多岐に渡ります。ほぼ同じマシンコード(命令)を実行しますが、命令ごとの実行速度はまちまちです。それは同じインテル社製でもいえることで、前回も触れましたが、現行種であるPentium4とCore2Duo、Core i7などでも異なります。これはどういうことかというと、CPUの種類によって速度最適化(最高の実行速度がでるようにすること)の手法も異なるということです。これは実行速度が命のプログラムにとっては面倒な話で、真の最適化をしようとすると、実行前にCPUの種類をチェックし、それに合わせたプログラムを実行するようにしなければなりません。なんだか、そのチェックと場合分けにかかるロスの方が大きくなるんじゃないかと心配になるくらいです。でも、CPUメーカーの最適化関連の資料を見ると「そうしろ」と書いてあります(^◇^;)。 | ||
| いくつか例をあげてみましょう。Pentium4はシフトやローテート命令が遅いCPUで、他のCPUが通常1クロックで実行するところ、4クロックもかかります。これは正直いってショックな事実です。つまり、Pentium4で走るプログラムには可能な限りシフト系命令を使わない方が良いのです。例えば、レジスタの値を左に3ビットシフトしたいときは、 | ||
|
SHL EAX, 3
|
||
| とはせず、 | ||
|
ADD EAX, EAX
ADD EAX, EAX
ADD EAX, EAX
|
||
| とした方が高速になる計算です(Pentium4のADD命令はレーテンシもスループットも0.5だが、二つの命令に依存関係があるので、この場合は2倍程度高速になるものと思われる)。これが右シフトだとSHR命令を使わざるを得ないので、高速化はできません。 また、コンディショナルセット命令のSETccもPentium4は低速で、驚くことに5クロックもかかります。PentiumMやCoreDuoなどでは当然のように1クロックです。この命令はそもそもジャンプ命令を減らしてパイプラインの乱れを抑えて高速化に寄与するはずの命令ですから、なんのこっちゃと思ってしまいます。クロック計算上は比較命令と条件ジャンプを組み合わせた方が高速になります(分岐予測がヒットした場合)。 意外なところで(?)、Pentium4では8bitレジスタの扱いに注意が必要で、BHレジスタやDHレジスタなどの16bitレジスタの上位8bitに位置するレジスタのアクセスに時間がかかります。これは命令を実行する前に内部で右にシフトしてから処理するためです。小さなループの中で8bitレジスタを使用する場合は下位の8bitレジスタを使用するようにしなければ効率が落ちてしまいます。 他にも乗算を行うIMUL命令がPentium4では14クロックかかるのに対して、Core系CPUでは3~4クロックで処理が完了します。これはCore系CPUでは、定数の乗算でもシフトや加算命令を使わずに素直に乗算命令を使った方が高速な場合があるということです。 まあ、現状を見ているとPentium4は消えそうな感じなので、これらのことは今後は考えなくても良いのかもしれません。ちなみに、AMDのPhenom x3/x4 CPUでは、キャリーを含むローテートなどのシフト系命令を始め、SETxx命令、ADC/SBB命令などもすべて1クロックで実行されます(レジスタオペランド)。でも、このようにCPUによってかなり性質が異なるということを憶えておくと、ひと味違ったプログラムを書くことができるかもしれません。 |
||
| さて、これまでの話は今回の余談です(^_^;)。本題は最近完全に主流となったマルチコアCPUの話です。「マルチCPUって本当に速いの?」という疑問にお答えできればと思います。 マルチCPUという形態も、最近は「マルチコアCPU」や「HT(ハイパースレッディング)テクノロジ」が登場し、区別が曖昧になっている人もいるかと思います。ここでもう一度それぞれを確認してみましょう。 マルチCPU(マルチプロセッサ)・・・複数のCPUチップで構成されるマシン マルチコアCPU・・・ひとつのCPU内に複数のCPU回路が入ったチップ HTテクノロジ対応CPU・・・ひとつのCPU回路内に論理的なCPUを2つ設けたCPU 以上のように考えるとわかりやすいと思います。 |
||
| では、これらのマルチなシステムはどのように動作するのでしょうか。マルチコアCPUの起動時の動作を例に見ていくことにしましょう。これがわかれば他2つの動作もほぼ同様です。 まずは基本用語としてBSPとAPという言葉を理解してください。BSPは"Bootstrap Processor"の略で、起動時からメイン動作するCPUコアを指します。APは"Apprication Processor"の略で、要はBSPに従うCPUコアと考えてください。BSPはシステムによって起動時に動的に決定されます。このとき各コアは自分がBSPなのかAPなのかを内部フラグに書き込みます。そしてBSPが初期化を含むシステムの起動プログラムを実行し始めます。APは自身の初期化処理を実行します。初期化の終了したAPは待ち状態に入り(CLI & HLT命令実行)、LocalAPICからのIPI(CPU内部割り込み)を待つことになります。IPIを受けるとAPは指定されたアドレスからプログラムを実行するのです。また、BSPは割り込みをどのコアに処理させるか設定します。つまり、コアごとにどの割り込みを処理するかが決められるのです。例えばCore2Quadの場合、マウス割り込みをコア1が、キー割り込みをコア2が、ドライブ割り込みをコア3が、というように振り分けられるわけです。こののちOSが起動すれば、OSがドライバやアプリケーションをどのコアに実行させるかを決めることができます。WindowsやLinuxのようなマルチタスクOSであれば、同一メモリ上で複数のプログラムが同時に実行されても衝突が起きないようになっているので、同時に進行するアプリケーションやスレッドがある場合、とても効率よく実行されることになります。 |
||
| かなりかいつまんだ説明ですが、おおよその動作の仕組みはおわかりいただけたかと思います。最初の質問である「マルチCPUって本当に速いの?」の答えは、「OSとアプリケーション次第で結構速い」となるかと思います。Core2Duoのマシンを使ってみて、「WindowsXPでもかなりヤルな」という感想を持ちました。タスクマネージャを見ていると、意外とうまく処理を2つのコアに割り振っているのがわかります。これからはマルチの時代だなぁ~と実感いたします<(_ _)>。 | ||
| 参考文献:IntelR 64 and IA-32 Architectures Software Developer’s Manual | ||
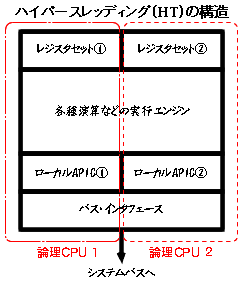 マルチコアCPUはインテルのCore2Duo/QuadやCore i7、AMDのAMD64x2やPhenomのことで、1つのチップ内にCPUコアが2~4つ入っています。コアがキャッシュを個別に持っているものと共有しているものとがあります。LocalAPIC
マルチコアCPUはインテルのCore2Duo/QuadやCore i7、AMDのAMD64x2やPhenomのことで、1つのチップ内にCPUコアが2~4つ入っています。コアがキャッシュを個別に持っているものと共有しているものとがあります。LocalAPIC