 |
||
| 連載第三回 「今時のCPUの命令と速度」 | ||
| H20/12/10 | ||
| 前回の予告で、今回もアセンブラレベルでのビット操作についてお話しする旨をお伝えしましたが、こちらはチラッとだけ絡めることにして、今時(平成20年末)のCPUのアセンブラ命令の話をメインにしようと思います。 | ||
インテルのSIMD命令(1つの命令で複数個のデータを同時に演算処理するアセンブラ命令)はMMX→SSE→SSE2→SSE3(HT対応Pentium・CoreSolo・CoreDuoなど)→SSSE3(Core2Duoなど65nmルールのチップ)→SSE4.1(Core2Quadなど45nmルールのチップ)→SSE4.2(Core i7)というように拡張されてきました。この中のSSE2への拡張のときにMMX命令がいくつか追加されています。その中のPMOVSMKB命令がビット関連の動作をします。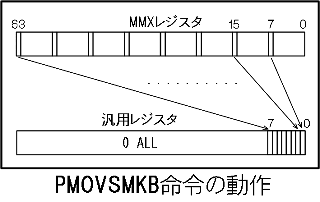 この命令は64bitのMMXレジスタ内の8つのバイトデータのMSB(最上位ビット)を集めて、指定した汎用32bitレジスタの下位1バイトに入れ、上位24bitを0で埋めます。また、128bitのXMMレジスタをソースにすることも可能で、この場合は16個のバイトデータのMSBを集めた1ワードを汎用32bitに入れ、上位16bitを0で埋めます。
この命令は64bitのMMXレジスタ内の8つのバイトデータのMSB(最上位ビット)を集めて、指定した汎用32bitレジスタの下位1バイトに入れ、上位24bitを0で埋めます。また、128bitのXMMレジスタをソースにすることも可能で、この場合は16個のバイトデータのMSBを集めた1ワードを汎用32bitに入れ、上位16bitを0で埋めます。これは立派なビット操作命令であるといえます。つまり、最新のSIMD命令にもビット操作命令があるということを言いたいわけです(^_^;)。どんなときに使用する命令なのか正直言って私の知識ではわからないのですが、各バイトデータ符号付きだと仮定すると、8または16個のバイトデータが全て正の値か、負の値かを一発でチェックすることができます。 |
||
| さて、ビットの話はこれまでにして、本題の今時CPUの話に移りましょう。 これまでCPUは高性能化を図るため動作クロック周波数をどんどん上げてきました。しかし、3GHzに達するとそれ以上はなかなか上げられなくなりました。これは半導体技術や発熱の問題で、今後も当分の間は変わらないと予測されます。そこで、CPU開発会社は先のSIMD命令を強化したり、CPUコアを複数組み入れたり、IPS(Instruction per sycle =1クロックで実行できる命令の数)を上げる方向で努力をしています。 ところが、CPUコアを増やすと歩留まりが悪くなってコストがかさみ、消費電力(=発熱)も増え、何より単一のプロセスを高速化できません。つまり、プログラムが上手くマルチスレッド化されていて、複数のCPUコアで効率良く走るようになっていないと処理速度が上がらないのです。これはプログラマには重荷です。 そこで、純粋に命令の実行効率を上げるアプローチも同時に行われています。より少ないクロック数で命令を実行できるように改良が続けられているのです。今時のCPUはどれくらいの効率で命令を実行しているのか見ていくことにしましょう。 |
||
| 今時のCPUの命令実行速度を見るときは、レーテンシとスループットの両面から見るべきなのですが、スループット(同じ命令を受け付け可能になるまでのクロック数)はほとんどの命令で1以下なので、今回はレーテンシ(実質的実行クロック数=命令を実行し始めてから完了するまでの所要クロック数)のみを見ていくことにします。 登場するCPUはインテルのCore2Duo(65nm版)とCore2Quad(45nm版)です。以後、それぞれC2DとC2Qと表記します。 まず、基本となる演算命令を見てみましょう。加減算命令のADDとSUB、および論理演算のAND、OR、XOR、NOTはすべて同じで、両CPUともレーテンシは1です。もう、完全にRISC化しちゃってます。ところが、ADC、SBBのようにキャリーを含める命令はレーテンシが2になります。これは使用頻度が少ない命令を犠牲にしているためと考えられます(でもPentium4ではレーテンシが8ですから、ずいぶん速くなったともいえますが)。これはローテートにも言えることで、通常のローテート命令であるROLとRORがレーテンシ1であるのに対し、キャリーフラグを含めたローテート命令のRCL、RCRがグッと遅くなっているのに似ています。 次にデータの移動命令であるMOV命令を見てみましょう。ここではブロック転送に使われるMOVSD命令を例にとります。この命令のレーテンシは1です。メモリからメモリへデータをコピーして、さらに2本のレジスタをインクリメント(+1)していながら1クロックで処理完了です。これは大量に実行される命令のひとつであるため、優先的に高速化が図られたものと思われます。実際にはキャッシュ以外のメモリにアクセスするときにウエイトが発生するため、額面通りの速度は出ないでしょうが、それにしても速いと言わざるを得ません。 C2DとC2Qでレーテンシが異なる例がBSWAP命令です。これはエンディアン(バイトの並び)を変更するときに使用される命令で、32bitデータの中身をバイト単位で順番を逆転させます。これがC2Dではレーテンシ2になのに対してC2Qでは4と、2倍も遅くなっています。これも通常は使用頻度が低いと見られたのかもしれません。 逆にC2Qの方が速い命令はいくつもあります。ビットサーチ命令のBSF/BSR命令はレーテンシが2→1、データの入れ替え命令のXCHG命令が3→2.5、そして除算命令のIDIV命令が17~41→13~23と圧倒的に速くなっています。それ以前のCPUが除算に60~80クロックもかかっていたことを考えると、本当に圧倒的であるといえます。 ちなみに乗算命令のIMUL命令はC2D、C2Qともレーテンシが3と、とても高速です。Pentium4では10クロック以上かかっていて、浮動小数点演算命令を使った方が速いと揶揄されていたのを考えると大きな進歩です。(ずっと昔、Cyrix社のx86互換CPUが乗算命令を3クロックで実行していたので、「すごい」とは言えないのですが・・・・) 使用頻度が比較的高い割には遅いのが、退避命令のPUSHです。C2Dでレーテンシが3ですが、Pentium4では1.5と半分です。MOVSD命令が1だったのを考えると釈然としない遅さです。このあたりは改善が待たれるところです。 高速化しているのは一般命令だけではありません。浮動小数点演算命令もがんばっています。顕著なところで平方根を求めるFSQRT命令が、C2D以前はレーテンシが58だったのに対し、C2Qでは6と、信じられないほど(約10倍)高速になっています。他、三角関数のFSINやFCOSも2割から3割高速化していますし、除算命令のFDIVが5倍以上高速化(32→6)しています。 ここまでくれば、MMXやSSEも速くなっていること、推して知るべしです。どちらも平方根や除算が、特にC2Qで顕著に高速になっています。また、SSSE3の命令群がC2Dに比べC2Qが2倍ほど速くなっています。C2Dのときは慌ててインプリメントしたのでしょうか? |
||
| 以上、もっと詳しく比較したかったのですが、インテルのデータシートが歯抜けになっていて、すべての情報がわかりませんでした。最適化マニュアルと銘打っているのですから、レーテンシ情報くらいは完全に載せてほしかったですね。今後の改善を望みたいところです。密かにCore i7のデータシートに期待してます。 | ||
| 参考文献:Intel64 and IA-32 Architectures Optimization Reference Manual | ||