続・過去の遺物 |
いまさらPC-9801
小手先技巧講座[後編] |
フッ……86なんて… 杉之原名人 |
|
|
第5話:アナログパレットの利用
PC-9801Vシリーズのあまり使われない機能の中に4096色のアナログパレットがあります。私も今までグラフィックツールソフトの他にこの機能を利用したソフトを見たことがありません。が、これも利用しない手はないというもの。ビジネスソフトに、ゲームソフトに、発想次第ではいくらでも応用できることと思います。例えばモノトーンの画面でも、郷愁を誘う微妙なセピア色のワークシートとか目に優しく気持ちの落ちつくグローブグリーンのテキストエディタなど、ちょっとした色使いでかなり面白い効果を出せる場合も多いと思います。また、ゲームなどの分野であっても、重厚なメタリック感覚のキャラクタやリアルな爆発シーンなど大きな効果を期待できます。
それでは早速プログラミングに入りましょう。Vシリーズにはハードウェア的に2つのカラーモードが存在します。それぞれ8色グラフィックモード、16色グラフィックモードと呼ばれ、前者が従来機とのコンパチモード(8色パレット)で後者が今回利用する4096色パレットが使用できるモードです。「16色」というのは、Vシリーズ以降の機種はRGB3画面の他にI(インテンシティー)(=明度)の画面が追加され、同時16色表示が可能になったことに由来します。 PC-9801のパレットポートはかなり異常でプログラマ泣かせでありまして、I/Oアドレスが連続しているわけでもなければパレットコードの順に並んでいるわけでもありません。おまけにポートが4バイトしかなく、従来コンパチの8色パレットの場合は上下2つのニブル(4bit)に分割して使用しなければなりません。はっきり言って完璧に人を馬鹿にしています。 幸い4096色パレットの設定の場合は8色のときほど苦労はなさそうです。I/Oポートを【表1】に示します。
|
| PORT |
DATA |
XPLANATION |
| A8H |
|
パレットアドレス設定ポート(0~15) |
| AAH |
|
緑パレットの色の濃度(0~15) |
| ACH |
|
赤パレットの色の濃度(0~15) |
| AEH |
|
青パレットの色の濃度(0~15) |
|
|
|
|
A8H~AEHまでのI/Oアドレスは常に【表1】のようになっているのではなく、I/Oポート6AHに01Hを出力して16色グラフィックモードを選択することによって初めてこのようになります。 |
| 【表1】 |
さて、パレットの設定の仕方ですが、わずか4バイトのI/Oポートを用いて4096色を表現するわけですから、従来のように3bitのパレットコードを出力するだけではとても済みません。まずA8Hにカラーコード(0=黒~15=明るい白)を出力し、次いでそのコードに割り当てる色をGRBそれぞれ16段階(4bit)でAAH,ACH,AEHに出力、設定します。ここで注意することは、VM2/VF2のように実際にはインテンシティーVRAMが載っておらず(オプション)16色モードに設定しても8色しか使用できない機種の場合は、出力するカラーコードが0及び9~15になることです。ちなみにカラーコード8はグレー(灰色)になります。
何はともあれサンプルプログラムを見てみましょう。一目瞭然だと思います。このプログラムを走らせると画面をフェードイン・フェードアウトします。原理は簡単で、グラフィックVRAMの黒のカラーコードに暗色の白から明色の白へ15段階でパレットコードを割り当てるわけです。ま、リストを見てください。ただ、このプログラムはSLR社のオプティマイズアッセンブラで開発してありますので、マイクロソフト社のMASMだとエラーを出すかもしれません。そのときは適宜修正してください。
|
;------------------------------------------------------------
CODE SEGMENT
ASSUME CS:CODE,DS:CODE
;
START:
MOV AL,8 ;グラフィック画面表示。
OUT 68H,AL ;
MOV AL,0DH ;
OUT 0A2H,AL ;
MOV AL,1 ;16色モード選択。
OUT 06AH,AL ;
MOV CX,15 ;パレットコード初期値。
FADE01: MOV AL,8 ;カラーコード8(黒)を設定。
OUT 0A8H,AL ;
MOV AL,15 ;
SUB AL,CL ;
OUT 0AEH,AL ;BRGの順に出力。
OUT 0ACH,AL ;
OUT 0AAH,AL ;
MOV AL,5 ;タイム・ウエイト。
CALL WAIT1 ;
LOOP FADE01 ;
;----------------------------------------
MOV CX,15 ;
FADE05: MOV AL,8 ;
OUT 0A8H,AL ;
MOV AL,CL ;
OUT 0AEH,AL ;
OUT 0ACH,AL ;
OUT 0AAH,AL ;
MOV AL,5 ;
CALL WAIT1 ;
LOOP FADE05 ;
;----------------------------------------
MOV AH,04CH ;プログラム終了。
INT 21H ;
;------------------------------------------------------------
WAIT1 PROC NEAR ;タイムディレイ・サブルーチン。
PUSH AX
PUSH CX
CMP AL,0
JE WAIT1_99 WAIT1_00:
MOV CX,5000 WAIT1_01:
NOP
NOP
NOP
LOOP WAIT1_01
SUB AL,1
JNE WAIT1_00 WAIT1_99:
POP CX
POP AX
RET
WAIT1 ENDP
;-----------------------------------------------------------
CODE ENDS
END START
|
|
|
第6話:ちょっとひと休み(SLR社製OPTASMについて)
 MS-DOS用のアッセンブラと言えばマイクロソフト社製のマクロアッセンブラである“MASM”が有名かつ主流のようです。このMASM、アメリカではすでにバージョン5.0が発売されており、その機能にも磨きがかかってきました。しかし、この独占を許すまじとばかりに、Z80ASMで有名な米SLR社がMS-DOSアッセンブラ界に殴り込みをかけてまいりました。その名もオプティマイズアッセンブラ“OPTASM”。そのスペックはというと、MASM V5.0完全上位コンパチブル。(実際には『完全』ではないようで、私もMASM用のとあるマクロライブラリを使用した際にエラーを出しまくられまして少々がっかりしました。おそらくバグでしょう。)本当に終わったのか?と思ってしまうような超高速性。(MASM V3.0と比べると、なんと15倍程度。)それでいながら条件ジャンプの自動最適化処理を行なうため、NEARジャンプとSHORTジャンプを使い分ける必要がありません。他にもローカルラベル機能やクロスリファレンサ内臓など、うれしい機能が満載されています。 私は一人で一気にプログラムを組む関係上分割アッセンブルは避けたいわけで、先日も依頼ソフトを完成させたところソースサイズが80Kバイトを越えてしまいました。これをMASM V3.0にかけますと、RAMディスクを使用しているにもかかわらずアッセンブルに2分以上もかかってしまいました。これにしびれを切らした私は大枚3万9800円(3万5000円にまけてもらいましたが)をはたいてOPTASMを購入したのです。結果は驚き、10秒足らずでアッセンブルが終了しました。その日からアッセンブルが楽しくなったのは言うまでもありません。現在もOPTASMを愛用していますが、ついこの前、ふとMASMの遅さをもう一度実感してみようと思い立ち、開発中の30K程度のソースをMASMにかけてみたのです。OPTASMだと3秒足らずで帰ってきますから、MASM(V3.0)だと40秒以上かかる計算になります。ところがそのとき私の見たものは、出るわ出るわのエラーの山でした。OPTASMでは“0 errors”と表示されるのに…………そう、オプティマイズの影響とV3.0のバグのために発生するものでした。これでおわかりでしょう。私はもうMASMを使えない身体になってしまったのです。 また、オブジェクトサイズにも違いが現れます。OPTASMの作成したOBJファイルはMASMのものよりも小さくなるのです。これはJMP命令が多く使用されていればいるほどこの差は大きくなります。OPTASMは不用なNOP命令を全く生成しないためです。MASMはNEARジャンプ(+127/-128)が2バイト命令、SHORTジャンプ(+32767/-32768)が3バイト命令であることからパス1実行時にとにかく3バイト確保し、パス2でNEARジャンプだと判断されると余分となった3バイト目にNOPを挿入するのです。 現在MASMのV5.0は日本国内では販売されていません。しかしこれの上位コンパチのOPTASM(V0.96)は国内代理店を通して現在販売されております。これは何と言ってもおすすめ品です。私個人にしてみれば腹が立つのですが、現在は定価33,800円と6000円安で販売されております。(私のように発売前から注文をしていると6000円損したことになってしまいました。ちなみに私の購入したフロッピーのシリアルNo.は「6」でした。おまけにタイトルはボールペンの直筆ですし。) MS-DOS用のアッセンブラと言えばマイクロソフト社製のマクロアッセンブラである“MASM”が有名かつ主流のようです。このMASM、アメリカではすでにバージョン5.0が発売されており、その機能にも磨きがかかってきました。しかし、この独占を許すまじとばかりに、Z80ASMで有名な米SLR社がMS-DOSアッセンブラ界に殴り込みをかけてまいりました。その名もオプティマイズアッセンブラ“OPTASM”。そのスペックはというと、MASM V5.0完全上位コンパチブル。(実際には『完全』ではないようで、私もMASM用のとあるマクロライブラリを使用した際にエラーを出しまくられまして少々がっかりしました。おそらくバグでしょう。)本当に終わったのか?と思ってしまうような超高速性。(MASM V3.0と比べると、なんと15倍程度。)それでいながら条件ジャンプの自動最適化処理を行なうため、NEARジャンプとSHORTジャンプを使い分ける必要がありません。他にもローカルラベル機能やクロスリファレンサ内臓など、うれしい機能が満載されています。 私は一人で一気にプログラムを組む関係上分割アッセンブルは避けたいわけで、先日も依頼ソフトを完成させたところソースサイズが80Kバイトを越えてしまいました。これをMASM V3.0にかけますと、RAMディスクを使用しているにもかかわらずアッセンブルに2分以上もかかってしまいました。これにしびれを切らした私は大枚3万9800円(3万5000円にまけてもらいましたが)をはたいてOPTASMを購入したのです。結果は驚き、10秒足らずでアッセンブルが終了しました。その日からアッセンブルが楽しくなったのは言うまでもありません。現在もOPTASMを愛用していますが、ついこの前、ふとMASMの遅さをもう一度実感してみようと思い立ち、開発中の30K程度のソースをMASMにかけてみたのです。OPTASMだと3秒足らずで帰ってきますから、MASM(V3.0)だと40秒以上かかる計算になります。ところがそのとき私の見たものは、出るわ出るわのエラーの山でした。OPTASMでは“0 errors”と表示されるのに…………そう、オプティマイズの影響とV3.0のバグのために発生するものでした。これでおわかりでしょう。私はもうMASMを使えない身体になってしまったのです。 また、オブジェクトサイズにも違いが現れます。OPTASMの作成したOBJファイルはMASMのものよりも小さくなるのです。これはJMP命令が多く使用されていればいるほどこの差は大きくなります。OPTASMは不用なNOP命令を全く生成しないためです。MASMはNEARジャンプ(+127/-128)が2バイト命令、SHORTジャンプ(+32767/-32768)が3バイト命令であることからパス1実行時にとにかく3バイト確保し、パス2でNEARジャンプだと判断されると余分となった3バイト目にNOPを挿入するのです。 現在MASMのV5.0は日本国内では販売されていません。しかしこれの上位コンパチのOPTASM(V0.96)は国内代理店を通して現在販売されております。これは何と言ってもおすすめ品です。私個人にしてみれば腹が立つのですが、現在は定価33,800円と6000円安で販売されております。(私のように発売前から注文をしていると6000円損したことになってしまいました。ちなみに私の購入したフロッピーのシリアルNo.は「6」でした。おまけにタイトルはボールペンの直筆ですし。)
|
|
|
第7話:V30の使いこなし
以前、零壱症候群第一号で「V30の話」をいたしました。ここではその続きを兼ねまして8086との差やアッセンブラプログラミングの高速テクニックなどを紹介します。
●回数指定SHIFT命令
8086にはCLレジスタにより回数を指定するSHIFT命令があることは周知の通りです。1ステップの命令で最大15回までの任意シフトができるわけですから、定数乗除算やビット編集にはもってこいの命令のように思われます。
確かにソースレベルではまことに便利なのですが、オブジェクトレベルになると話は別です。実行速度がかなり遅くなるのです。8086CPUの場合、レジスタの1回シフトに要するクロックは最低の2クロックですが、回数指定シフトの場合は1回のシフトでも12クロックもかかってしまうのです。【表.1】を見てください。
【表.1】 (8086の場合)
SHL DX,1 ・・・・・ 2 Clock
SHL DX,CL ・・・・・ CL*4+8 Clock |
CLによる回数指定シフトの場合は、基本8クロックにシフト回数×4クロックを加えた分のクロックを消費します。ですから、 ex.1の場合を計算すると 6×4+8=32 となります。これに対して1回シフト命令を任意回数繰り返した場合は 6×2=12 となり、6回シフトする場合は約2.7倍も高速になります。ちなみに2回シフトの場合は4倍、15回シフトの場合は約2.3倍と、共に回数指定をしない方がずっと高速です。8086の場合は回数指定SHIFT命令の使用は、高速性が必要なく、ビット操作の多用が必要なとき以外は控えるべきでしょう。
以上の話はあくまで8086のときのことで、これがV30になるとかなり話は変わってきます。表.2を見ればわかるように、回数指定シフトのクロック数が減っています。
【表.2】 (V30の場合)
SHL DX,1 ・・・・・ 2 Clock
SHL DX,CL ・・・・・ CL+7 Clock
SHL DX,imm ・・・・ imm+7 Clock |
これから計算しますと、7回以上シフトするときは回数指定SHIFT命令を使用した方が良いことになります。ちょうど7回シフトした場合は共に14クロックですが、当然サイズの小さい回数指定シフトの方がよいでしょう。これはV30が定数指定によるシフトが可能なためです。8086のようにCLレジスタによる指定しかできないと、CLレジスタへ回数をロードする手間がかかってしまうので11回以上シフトしないと元がとれないことになってしまいます。7回以上一度にシフトすることはめずらしいとは思いますが、いちおう憶えておくことをおすすめします。
●DEC,INC命令の不条理
DEC,INC命令はZ80や6809などの8bitCPUにも存在するオーソドックスな命令です。もちろん8086にもあり、任意の汎用レジスタやメモリの内容を±1することができます。
ところが8086の場合、この命令の実行サイクルが不条理なのです。Z80などでは当然8bitレジスタに対するINC,DEC命令の方が16bitのペアレジスタの場合よりも速いのですが、8086ではこれが逆になります。つまり、16bitレジスタのINC,DEC命令が2クロック、8bitレジスタのINC,DEC命令が3クロックと16bitレジスタの方が高速になっているのです。ゆえに、より高速にDLレジスタ (8bit)の値を±1したいときは、DHレジスタの破壊を考慮しながらDXレジスタをINC,DECすべきです。ただし、これは8086のときだけで、V30の場合は8bit/16bitどちらでも2クロックです。
●ブロック転送 8086
V.S. V30
インテル系CPUの特徴のひとつであるブロック転送専用命令は、8086ではストリング命令として用意されています。MOVS命令がそれで、バイト転送/ワード転送どちらを選択することも自由です。この命令の簡便性、高速性は使用経験ある方は実感済みのことと思います。 ではここで、8086のMOVS命令の高速性を証明するために、通常のMOV命令を使用した等価ルーチンとの所要クロックの差を見ていくことにしましょう。
MOVSを使わない場合
TLOOP:MOV AX,[SI] 13(11)Clock
MOV [DI],AX 14(9)Clock
INC SI 2(2)Clock
INC DI 2(2)Clock
+) LOOP TLOOP 17(13)Clock
---------------------------------
48(37)Clock |
MOVSを使った場合
+) REP MOVSW 20(10)Clock
---------------------------------
20(10)Clock |
|
注)
括弧内の数字はV30の場合。 |
|
|
| 【表.3】 |
|
|
まず断わっておくことにしますが、【表.3】のクロック数は2回目以降、最終回の直前までの場合を指しています。ちなみにMOVSを使った場合の第1回目は26(11)Clockとなり、MOVSを使わない場合の最終回は36(29)Clockとなります。
さて、【表.3】をご覧になればおわかりのように、8086のストリング命令を使用した場合としなかった場合では実に約2.5倍もの実行速度の差が生じます。このことは脳裏にしっかりととどめておいてください。たかだか3ワード程度のデータ転送だからといって1ワードずつレジスタを介して転送するよりも、多少の初期設定をしてでもストリング命令を使用した方が高速な場合だって多々あるのです。V30ならばなおさらです。 |
ここでV30のケースがでましたが、【表.3】の括弧内を見れば一目瞭然なように、ストリング命令を使用しない場合でも25%程度、使用した場合はちょうど2倍も8086より高速なのです。このストリング命令の高速化はV30の特徴のひとつでして、PC-9802がVシリーズになってからグラフィックを多用したゲームなどの速度がグ~ンとアップした理由のひとつはここにあるといってよいでしょう(VRAMアクセスのウエイトが下がったのも大きいですが)。V30プログラマの人はここんとこをうまく利用しましょう。
(※以上はメモリアクセスに際してウエイトがかからないという前提で計算したものです。)
|
|
|
●ビットフィールド操作命令
V30特有の命令にビットフィールド操作命令があります。これは他の16bitCPUにも類を見ないものです。
通常、メモリにデータを格納する際やメモリからレジスタにデータをロードする際などは、バイト単位、あるいはワード単位で行なわれます。3bitや14bitといった中途半端なビット長でのロード/ストアはできないのが普通です。こういった場合は、AND,ORといった論理演算やSHL,RORなどのシフト命令を使用して実現しなければなりません。
V30のビットフィールド操作命令を使うと、1~16bitの任意ビット長のデータをメモリ空間上の任意のビット位置に格納したり、またレジスタにロードしたりすることができます。言うなれば「ビット単位のブロック転送命令」です。これはグラフィックVRAMを操作する際にはこの上なく高速かつ便利であります。例えばPC-9801のN-88BASICのPUT@文,GET@文を考えてみてください。任意の大きさのグラフィックデータをドット単位の任意の画面位置に表示、あるいは画面から取り込みを行なうわけですから、結構複雑なビット操作が必要になることはご想像いただけることと思います。
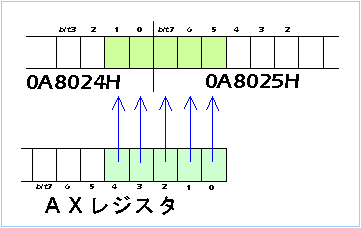
| 右の【図.1】は青VRAMに対してビットフィールド操作命令のINS命令を実行したときの様子です。この例ではAXレジスタの下位5bitを0A8024H番地の下位2bitから0A8025H番地の上位3bitにかけて転送します。INS命令を使用すると、 |
|
|
|
| 【図.1】 |
(MOV AX,10101B ;AX=WRITEデータ)
MOV DX,0A800H ;
MOV ES,DX ;ES=転送先セグメント
MOV DI,24H ;DI=BYTEオフセット
MOV DL,6 ;DL=bitオフセット
INS DL,5 ;5ビット転送
となります。これを8086のコードで書くと、
(MOV AX,10101B ;AX=WRITEデータ)
MOV DX,0A800H ;
MOV DS,DX ;DS=転送先セグメント
MOV DI,24H ;DI=BYTEオフセット
ROR AX,1 ;shift right 3bit
ROR AX,1 ;& copy LSB to MSB
ROR AX,1 ;& repeat 3times.
AND AL,00000011B ;mask high 6bit.
OR [DI],AL ;DATA(2bit) WRITE.
AND AH,11100000B ;mask low 5bit.
OR [DI+1],AH ;DATA(3bit) WRITE.
このようになってしまいます。ここでは2バイトにまたがる例でしたが、これが3バイトにまたがる場合だとこんなもんでは済みません。INS命令を使用すれば第2オペランド(アンダーライン部分)を例えば14にするだけで済みますが、8086コードだとさらに複雑になってしまいます。速度は言うに及ばず、平均でも3~5倍高速化されます。
余談ですが、PC-8801VAのCPUであるμPD9002はV30同様、NECオリジナルの8086コード上位コンパチの機能を持っていますが、V30ほどの機能は有していません。言い方を変えれば、V30からいくつかの機能を削減し、8080エミュレート機能をZ80エミュレート機能に変えたCPUであるということができます。では、どのような機能が削減されたかというと、このビットフィールド命令やBCDストリング演算命令なのです。
|
|
|
●STOS命令の高速性
STOS命令も知らないと損をする命令のひとつでしょう。どのくらい速いかというと、
|
共通部分
XOR AX,AX 3(2)Clock
MOV DX,2 4(4)Clock
MOV DI,AX 2(2)Clock
MOV CX,4000H 4(4)Clock |
STOSを使わない場合
LB1: MOV [DI],AX 14(9)Clock
ADD DI,DX 3(2)Clock
+) LOOP LB1 17(13)Clock
---------------------------------
48(37)Clock |
STOSを使った場合
+) REP STOSW 13(6)Clock
---------------------------------
13(6)Clock |
|
|
これくらい速くなります(【表.4】)。例によってクロック計算は初回と最終回を除くループ内部の合計、括弧内はV30での値です。
この場合、メモリを32Kバイト0でクリアするルーチンになります。ご覧のようにSTOS命令をREPプリフィクスと併用して使用すると8086で2.6倍、V30で4倍も高速化します。
STOS命令はメモリを一定のデータで埋める用途以外にはあまり使い道はないように定説化されていますが、数列や演算テーブルの作成など応用はまだまだあると思われます(リピートプリフィクスは使用できませんけど)。特にV30の場合はそれによってかなり高速化が図れます。
(※これもメモリアクセスに際してウエイトがかからないという前提で計算したものです。) |
| 【表.4】 |
|
|
|
●ビット操作命令
Z80のプログラミングをされたことのある方はビット操作命令のありがたみがおわかりになると思います。任意1ビットのセット,クリア,テストが1ラインで実現できるのですから。8080でこれをやろうとすると大変。シフトやAND,ORの連発になります。実は8086も8080と同様で、任意のビットを操作するには論理演算の連発にならざるを得ません。
ところがV30にはZ80以上に完備したビット操作命令が用意されているのです。セット,クリア,テストの他に反転(NOT)が追加され、アドレッシングも豊富になりました。8086の未定義コード“0FH”で命令を拡張しています。
ビット操作命令はBASICのPSET文を実現するのに便利そうですが、他にもテキストのアトリビュートをいじったり、不揮発性メモリスイッチの設定を変えたり、また効率の良いデータ形式に、と応用は限りないと思います。また、実行速度も申し分なく高速です(レジスタの場合3~5クロック)。
●ブロックPUSH/POP
V30特有命令の中でも光っているもののひとつです。V30ニモニックでは、
push R
pop R
と表現します。わずか1ラインで8ライン分のPUSH/POPを行なうのですから嬉しさいっぱい夢いっぱいです。8本の汎用レジスタをもれなく一気にスタックに放り込んだり戻したりしてくれます。さて問題の速度ですが、【表.5】を見てみましょう。
| PUSHもPOPも8回行なえば64クロックを消費しますから、PUSH_Rで1.8倍、POP_Rでも1.5倍は高速になります。また、これだけ速度に余裕があると、なにも全レジスタをPUSH/POPする場合のみに使用する必要もありません。例えば、あるサブルーチンで5本の汎用レジスタをPUSHしてPOPする必要があるとき、合計10回のPUSH/POP=80クロックのクロック消費があるわけです。しかし、PUSH_R+POP_R=78クロックと、16回のPUSH/POPがあるにもかかわらずより高速です。つまり、5本以上のレジスタの退避復元が必要なときはブロックPUSH/POP命令を使用した方が、高速かつ省メモリということです。決して忘れてはいけません。 |
|
PUSH R ・・・・・・ 35Clock
POP R ・・・・・・ 43Clock
PUSH AX ・・・・・・ 8Clock
POP AX ・・・・・・ 8Clock
(AXに限らず他のレジスタも同様)
|
|
|
| 【表.5】 |
(※これもメモリアクセスに際してウエイトがかからないという前提で計算したものです。)
|
|
|
最終話:特に脈絡ありません
先日、NECからV30の改良型と呼ぶべきV33が発表になりました。16MHzで2.8MIPS、10MHzのV30に比べ4倍の処理能力といいますからなかなかのものです。物理アドレス空間も16Mバイトになり、内部回路も完全ワイヤードロジックになりました。これによってインテルとの訴訟問題も解決するとのことです。今秋発表のNECのPC-9801シリーズの新型にもおそらくV33が載ってくることでしょう。今から楽しみですね。(「心から……」ではないけど)
|
|
|
※この原稿は1990年頃に書かれたものです。 |
|
|
|
|